During this weekend I attended the
Open source Summit held at IIIT Hyderabad which was on 13-14 (I was unable to attend the event on the second day :( ). On Saturday morning I took the MMTS from the station nearby home and came to HafeezPet and from there reached
IIIT by auto around 11 am.
 The first session I attended was on BeleniX, opensolaris LiveCD project - Moinak Ghosh,I arrived the conference room, while the presentation was halfway around . The presenter was upgrading the openSolaris and while it was going on, other applications were executed !! He was explaining how openSolaris and ZFS is useful in production ready environment. He demonstrated creating separate snapshots. He explained about using DTrace, which can be used to dynamically inject debug codes while the application is running (can be used for debugging kernel). He explained about the difference between zones in Open Solaris and virtualization, concept of RAMDisk etc. The session was good as practical samples are demonstrated.
The first session I attended was on BeleniX, opensolaris LiveCD project - Moinak Ghosh,I arrived the conference room, while the presentation was halfway around . The presenter was upgrading the openSolaris and while it was going on, other applications were executed !! He was explaining how openSolaris and ZFS is useful in production ready environment. He demonstrated creating separate snapshots. He explained about using DTrace, which can be used to dynamically inject debug codes while the application is running (can be used for debugging kernel). He explained about the difference between zones in Open Solaris and virtualization, concept of RAMDisk etc. The session was good as practical samples are demonstrated.
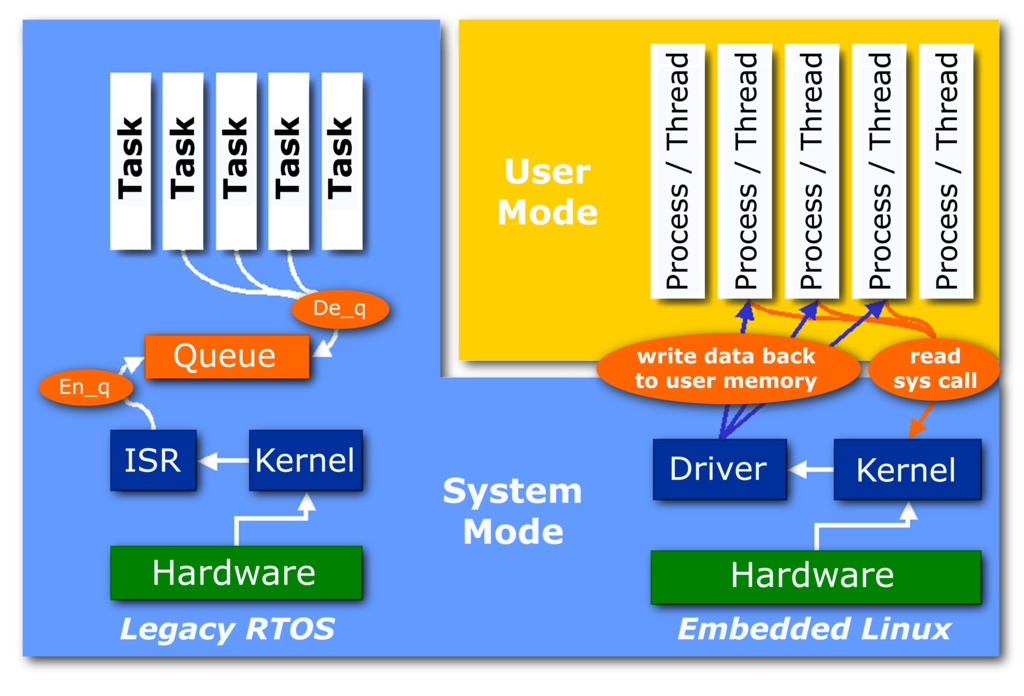
Next session was more interesting was, by Mahesh Patil from National Ubiquitous Computing Research Center – CDAC, Embedded Linux and Real time Operating systems. I really enjoyed and understood the technology. When I was in my college (MCET Trivandrum) we used to conduct lot of seminars. Sensor networks, nano technology were most presented those days. But this session as a great experience as he had to show something cool. He had a board with ARM processor and he demonstrated loading the Linux OS into it. He explained about ToolChains , how it can be used, packaging the kernel images etc. He described how an embedded OS is different from RTOS and about the preemptive nature of RTOS.RTOS uses the dual kernel approach in which the interrupt handling latency can be reduced by a kernel handling it and other operations by other kernel. The core kernel operations are given a low priority as the other tasks which are to be executed with higher priority in the queue. I came to know that most of the embedded Linux is based on POSIX compliance, but in Japan it is MicroItron. He explained about ECOS a configurable OS which can be configured for embedded or real time. Then about the Smart Dust project, cool futuristic technology; tiny devices floating around which communicate within a small range where they sleep most of the time. I was wondering about how huge the data will be produced by these devices. Think about real-time heat maps of different boxes holding vaccines those are distributed around the world! (Now pharmaceutical companies have a device kept inside the package to record the temperature when it was packed and check the change in temperature when opened) .Also came to know about the 3KB Linux – TinyOS ! Cool and simple… even though I am not from electronics background ...
 On to the stage, was a geek – Arun Raghavan from Nvidia.He is a developer in Gentoo Linux community.I hasn't tried this Linux variant before. It's a linux for developers!! Any application can be customized for performance, maintainability creating ebuilds which will make it so flexible for developers. I think it will have a good learning curve as most of the installations and customizations can be done by a user .He demonstrated creating ebuilds for gtwitter a twitter client.He demonstrated the ease of using Portage which is a package management system used by Gentoo Linux.Visit Gentoo.org to know more about this linux.I really liked the article written by Daniel Robbins(Architect of Gentoo Linux) about the birth of it; read here .
On to the stage, was a geek – Arun Raghavan from Nvidia.He is a developer in Gentoo Linux community.I hasn't tried this Linux variant before. It's a linux for developers!! Any application can be customized for performance, maintainability creating ebuilds which will make it so flexible for developers. I think it will have a good learning curve as most of the installations and customizations can be done by a user .He demonstrated creating ebuilds for gtwitter a twitter client.He demonstrated the ease of using Portage which is a package management system used by Gentoo Linux.Visit Gentoo.org to know more about this linux.I really liked the article written by Daniel Robbins(Architect of Gentoo Linux) about the birth of it; read here .
 I attended another session which was on Hadoop by Venkatesh from Yahoo research team.Hadoop is an opensource project for large data centers .I was looking forward for this presentation as it is about the web 2.0 (cloud computing) and large scale computing (blogged before). It is a framework written in Java that supports data intensive distributed applications.To know more about large scale data processing using Hadoop you can read this paper.It has a file system called HDFS filesystem ( pure-Java file system !!) stores replicated data as chunks across the unRaided SATA disks.There is a name node and a cluster of data nodes like a master-slave system.Name node stores an inverted index of data stored across the file system.Concept is similar to Google File System and its cluster features.More about the concept here (Nutch) , here This framework can be used for processing high volume data integrated with lucene will help to create a quality search engine of our own.This framework is used by Facebook. In one of the Engineering @ Facebook's Notes explains why Hadoop was integrated . Read here. It is used by IBM(IBM MapReduce Tools for Eclipse), Amazon,Powerset (which was acquired by Microsoft recently),Last.fm ... Read more More hadoop in data intensive scalable computing.Related projects Mahout (machine learning libraries),tashi (cluster management system).
I attended another session which was on Hadoop by Venkatesh from Yahoo research team.Hadoop is an opensource project for large data centers .I was looking forward for this presentation as it is about the web 2.0 (cloud computing) and large scale computing (blogged before). It is a framework written in Java that supports data intensive distributed applications.To know more about large scale data processing using Hadoop you can read this paper.It has a file system called HDFS filesystem ( pure-Java file system !!) stores replicated data as chunks across the unRaided SATA disks.There is a name node and a cluster of data nodes like a master-slave system.Name node stores an inverted index of data stored across the file system.Concept is similar to Google File System and its cluster features.More about the concept here (Nutch) , here This framework can be used for processing high volume data integrated with lucene will help to create a quality search engine of our own.This framework is used by Facebook. In one of the Engineering @ Facebook's Notes explains why Hadoop was integrated . Read here. It is used by IBM(IBM MapReduce Tools for Eclipse), Amazon,Powerset (which was acquired by Microsoft recently),Last.fm ... Read more More hadoop in data intensive scalable computing.Related projects Mahout (machine learning libraries),tashi (cluster management system).
So it was worth as I was able to attend these sessions .... Thanks to twnicnling.org
{kind=link}
No comments:
Post a Comment